
Overview
The Robots.txt file is an important part of websites and search engine optimisation (SEO) that web designers and SEO specialists should be aware with. This file is critical in determining how search engines crawl and index web pages. Web designers may manage which sections of their website are available to search engines by using Robots.txt, ensuring that sensitive or irrelevant pages are not indexed.
What is Robots.txt?
Robots.txt is a plain text file that remains on the server of a website and directs search engine crawlers on which pages or portions of the website to crawl and index. It acts as a road map for search engine bots, directing them on how to browse the website’s content. These commands are expressed by “allowing” or “disallowing” a particular (or all) bots’ actions.
Syntax of Robots.txt
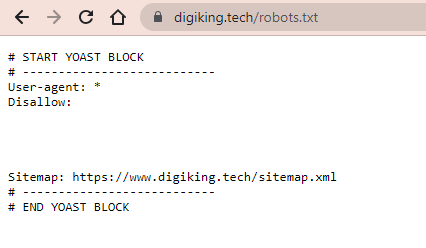
User-Agent: *
Disallow:
Sitemap: https://www.example.com/sitemap_index.xml
A simple robots.txt file would look like this:
Purpose of Robots.txt
The primary objective of Robots.txt is to improve a website’s visibility and control over the crawling and indexing process. It enables webmasters to convey their preferences to search engine crawlers, influencing how information on their website is indexed and presented in search engine results pages (SERPs). Webmasters may use Robots.txt to prevent certain sites from being crawled, secure sensitive information, and optimize the crawl budget by prioritizing important material.
Creating a Robots.txt file is a simple task. Begin by opening a simple text editor, such as Notepad, or your preferred code editor. Save the file with the name “robots.txt” and no file extensions. Once saved, use FTP or a file manager supplied by your hosting provider to upload the file to the root directory of your website.
Rules of Robots.txt
Robots’ Rules.txt the file is made up of directives that tell search engine crawlers how to interact with your site. Let’s look at the most important instructions included in Robots.txt:
1. User-agent
The “User-agent” directive defines which search engine crawler is subject to the following restrictions. If you wish to target all search engines, for example, you may use the wildcard character (*) as the user-agent value. If you wish to target a particular search engine, such as Google, use “User-agent: Googlebot.”
2. Disallow
The “Disallow” directive instructs search engine crawlers which portions of your website should not be crawled. Individual pages or whole directories might be specified. “Disallow: /private/” would, for example, block crawling of the “private” directory.
3. Allow
The “Allow” directive replaces a prior “Disallow” directive. It defines exceptions to the prohibited pages or directories. For example, “Allow: /public/page.html” would permit crawling of the specified page despite a general forbid directive.
4. Sitemap
The “Sitemap” directive tells search engines where to find your website’s XML sitemap. This makes it easier for search engine crawlers to locate and index your web pages. For example, “Sitemap: https://www.example.com/sitemap.xml” would be the sitemap’s URL.
Advanced Usage of Robots.txt
Beyond the fundamentals, Robots.txt provides extensive functionality that can improve the crawling and indexing of your website. Let’s look at some of the more complex techniques:
1. Wildcards
URL patterns can be matched using wildcards. The most frequent wildcard character is the asterisk (). “Disallow: /articles/” would, for example, block crawling of all URLs in the “articles” directory.
2. Delay in Crawling
The “Crawl Delay” directive specifies a time delay between future crawler requests. This can help with server load management and reducing excessive crawling. “Crawl-delay: 5”, for example, would add a 5-second give us among every request made.
3.No index
To block search engines from indexing certain sites, use the “No index” directive. This is especially handy for material that should not surface in search engine results. For example, “No index: /private/page.html” would prohibit the provided page from being indexed.
4.No follow
The “No follow” directive tells search engine crawlers not to follow links on a certain page. This is useful if you want to avoid crawling external links or sites that lead to irrelevant material. “No follow: /external-links/page.html” would, for example, prohibit the crawler from following any links on that page.
Common Mistakes with Robots.txt
While Robots.txt is a useful tool, it is critical to prevent common errors that might have a detrimental influence on your website’s crawling. Some frequent traps to avoid include:
Misconfigured directives: Make sure your directives are correctly stated and have no syntax problems.
Essential pages are being blocked: Take care not to mistakenly prevent vital pages from being indexed.
Assuming confidentiality: Because Robots.txt is a public file, it should not be used to conceal critical information.
Inadequate testing: Before releasing your Robots.txt file to your live website, always test it to verify it works as expected.
Importance of Robots.txt for SEO
Robots.txt is essential for improving your website’s SEO performance. You may prioritise the visibility of useful material while ensuring sensitive or irrelevant sites are not indexed by deliberately regulating which pages search engines crawl and index. Improving your Robots.txt file can result in higher search engine results, a better user experience, and more organic traffic.
Conclusion
Finally, Robots.txt is a critical tool in website optimisation and SEO. You may manage how search engine crawlers interact with your website by knowing its purpose, grammar, and sophisticated approaches. Use the power of Robots.txt to direct crawlers to useful material, secure sensitive information, and improve the visibility of your website in search engine results.